Trung tâm Khoa học công nghệ và Truyền thông Nghệ AnTrung tâm Khoa học công nghệ và Truyền thông Nghệ An
Trang thông tin điện tử
Trung tâm Khoa học công nghệ và Truyền thông Nghệ An
Ứng dụng trí tuệ nhân tạo trong nâng cao hiệu quả ứng dụng tìm kiếm trong mạng diện rộng của Đảng và mạng Internet
Thứ ba - 28/02/2023 11:052.2940
Hiện nay, việc nghiên cứu, ứng dụng các giải pháp trí tuệ nhân tạo để khai phá thông tin từ dữ liệu và hỗ trợ ra quyết định đang phát triển mạnh mẽ. Văn phòng Trung ương Đảng (TƯ Đảng) đã và đang triển khai hiệu quả hai hệ thống phần mềm tìm kiếm, tổng hợp thông tin dùng chung cho các cơ quan Đảng trong mạng thông tin diện rộng của Đảng và Phần mềm hệ thống thu thập, tổng hợp thông tin trên Internet hỗ trợ công tác tham mưu, thẩm định các đề án. Bài báo này sẽ mô tả các bước xây dựng, triển khai việc ứng dụng mô hình QAC (Query Auto Completion) cho việc tìm kiếm thông tin trong hai hệ thống nói trên, đồng thời đánh giá tính hiệu quả khi áp dụng hệ thống cho các phần mềm.
GIỚI THIỆU
Query Auto Completion (QAC) là một đặc trưng riêng biệt của các hệ thống tìm kiếm dựa trên văn bản (text), cho phép gợi ý các cách hoàn thiện câu truy vấn khi người dùng đang nhập dữ liệu. Tính hiệu quả của hệ thống này được đánh giá dựa trên khả năng phản hồi tức thời trong quá trình sử dụng các hệ thống phần mềm khi người dùng nhập các thông tin tìm kiếm dạng text, cũng như khả năng gợi ý các câu tìm kiếm dựa trên văn bản mà người dùng đã nhập vào.
QAC đã được nghiên cứu rộng rãi trong những năm gần đây và được phân loại vào 2 dạng chủ yếu: heuristic models và learning-based models [5]. Mô hình heuristic sử dụng kết quả dự báo từ một vài nguồn cho một câu truy vấn và tính toán điểm cho các lựa chọn đưa ra dựa vào một số ít đặc trưng trong khi mô hình dựa trên học sâu (learning-based) quy bài toán QAC về bài toán ranking dựa vào cơ sở từ các nghiên cứu trong lĩnh vực LTR (Learning To Rank) [6]. Mô hình learning-based thường bỏ xa các mô hình heuristic [5] do dựa trên tập các đặc trưng nhiều hơn so với các mô hình heuristic. Các đặc trưng sử dụng chủ yếu thuộc về 3 dạng: time-sensitive, context-based và demography based. Các mô hình time-sensitive mô hình hóa sự phổ biến của các câu truy vấn. Sự phổ biến này thay đổi theo thời gian, chẳng hạn độ phổ biến theo tuần. Demography based dựa trên các đặc trưng về độ tuổi, giới tính,… thường bị giới hạn về dữ liệu người dùng và rất khó truy cập. Trong khi đó, các đặc trưng về ngữ cảnh (context-based) dựa trên các câu truy vấn đã thực hiện của người dùng, do đó hoàn toàn có thể thu thập và sử dụng.
Một số mô hình học sâu ứng dụng trong tìm kiếm dự báo (predictive search) bao gồm mạng nơ-ron hồi quy RNN (Recurrent Neuron Network), mạng LSTM (Long short-term memory), mô hình ngữ nghĩa ẩn tích chập (Convolutional Latent Semantic Model - CLSM). Mô hình ngữ nghĩa ẩn tích chập được đề xuất sử dụng bởi Bhaskar Mitra và cộng sự năm 2015 [2]. Các tác giả trong [4] và [9] đề xuất cách tiếp cận mô hình hóa ngôn ngữ end-to-end dựa trên mạng học sâu. Sida Wang và cộng sự [10] đề xuất xây dựng hệ thống tự động hoàn thành truy vấn dựa trên mạng nơron với khả năng mô hình hóa ngữ cảnh hiệu quả.
Điểm chung của các phương pháp dựa trên các mạng nơ-ron nhân tạo là yêu cầu phải có tập dữ liệu huấn luyện lớn để huấn luyện các mô hình. Tuy nhiên, một mô hình huấn luyện dựa trên tập dữ liệu cụ thể nào đó sẽ không áp dụng được cho một lĩnh vực thông tin khác. Ngoài ra, các mô hình học sâu nói trên thường được áp dụng cho tiếng Anh, không đáp ứng được cho tiếng Việt. Vì vậy, với các hệ thống thông tin tiếng Việt, trong đó có mạng thông tin diện rộng của Đảng, để áp dụng các cách tiếp cận trên, nhóm tác giả xây dựng và huấn luyện mô hình của riêng mình. Đến nay, chưa có đề tài, đề án nào nghiên cứu trí tuệ nhân tạo, ứng dụng tích hợp tính năng tự động hoàn thành từ khóa (AutoComplete) và gợi ý các từ khóa liên quan (AutoSuggestion) vào các ứng dụng tìm kiếm trong mạng diện rộng của Đảng và trên mạng Internet.
Trong bài báo này, nhóm tác giả thực hiện ứng dụng fastText để gợi ý các từ khóa từ đầu vào là xâu ký tự người dùng nhập vào trong quá trình sử dụng hai phần mềm tại Văn phòng Trung ương Đảng, đồng thời đưa ra mô hình thực hiện ứng dụng fastText, đồng thời mô tả từng bước khi áp dụng trong thực tế tại một phần mềm.
ĐẶT RA BÀI TOÁN VÀ ĐỀ XUẤT MÔ HÌNH ỨNG DỤNG
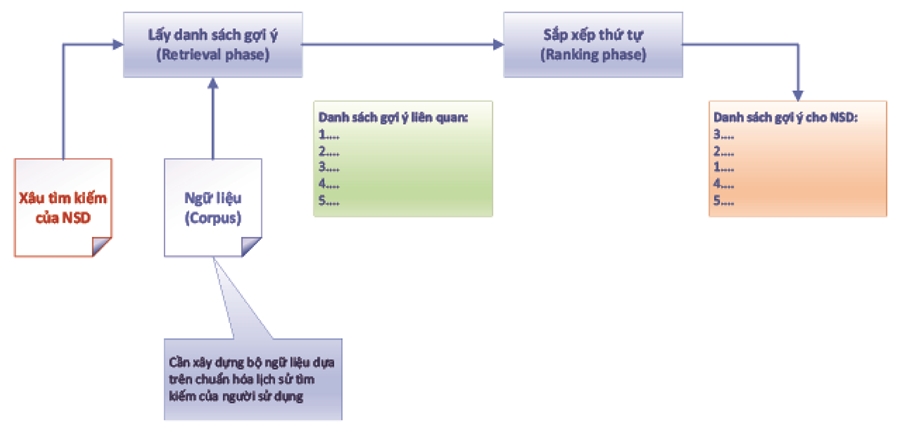
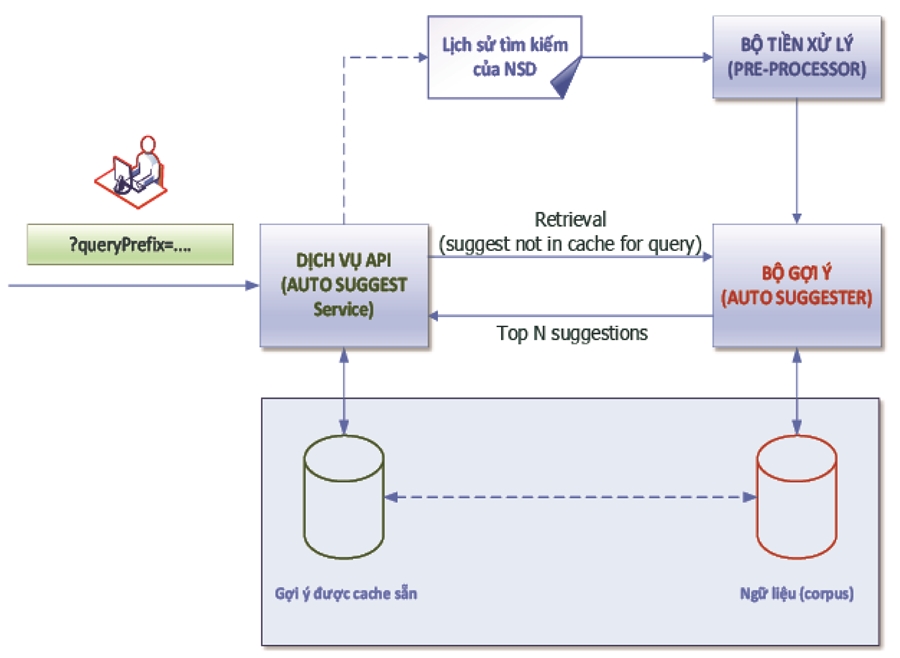
Bài toán cần giải quyết được mô tả như Hình 1 dưới đây:
Hình 1. Bài toán QAC tại Văn phòng TƯ Đảng.
Từ bộ ngữ liệu được thu thập (tiếng Việt), căn cứ xâu tìm kiếm của người dùng, hệ thống lấy danh sách gợi ý dựa trên ngữ nghĩa, rồi thực hiện xếp hạng dựa trên “khoảng cách” của các câu trong danh sách gợi ý để cho ra danh sách cuối cùng hiển thị cho người sử dụng. Danh sách này cần đảm bảo các yếu tố: có tiền tố (prefix) tương đồng và có ý nghĩa tương tự hoặc liên quan đến xâu tìm kiếm của người sử dụng.
Có thể nhận thấy, bản chất của bài toán QAC có ba vấn đề chính cần giải quyết: Một là, xây dựng bộ ngữ liệu tiếng Việt; Hai là, xây dựng module lấy danh sách gợi ý; Ba là, áp dụng thuật toán ranking sắp xếp thứ tự các kết quả để hiển thị cho người dùng. Căn cứ vào các thông tin khảo sát về dữ liệu mà hai hệ thống phần mềm của Văn phòng TƯ Đảng đã lưu trữ (chủ yếu là dữ liệu text), nhóm tác giả nhận thấy việc tìm kiếm của người dùng tập trung vào nội dung của dữ liệu mà hai hệ thống này quản lý.
Taihua Shao và cộng sự trong [11] áp dụng Word2vec để giải quyết bài toán QAC, tuy nhiên, các nghiên cứu cho thấy Word2vec không đáp ứng tốt đối với các từ hiếm gặp, hoặc bộ ngữ liệu được thu thập không đủ đa dạng. Trong khi đó, fastText là bộ thư viện được Facebook xây dựng và cung cấp giải quyết vấn đề đó của Word2vec, đồng thời cho phép hoạt động trên nền tảng các phần cứng thông dụng với hiệu năng tốt.
Để có thể lấy được danh sách gợi ý từ bộ ngữ liệu đã thu thập, nhóm tác giả áp dụng bộ thư viện fastText [1, 7, 8] từ Facebook để biểu diễn text trong ngữ liệu các câu tiếng Việt thành dạng vector. Sau đó, thực hiện huấn luyện mạng nơ ron dựa trên bộ thư viện fastText để xây dựng mô hình biểu diễn ngôn ngữ với bộ ngữ liệu câu đã thu thập được. Bộ thư viện fastText cũng cho phép ta tính toán mức độ tương đồng của câu tìm kiếm người sử dụng nhập vào dựa trên tính toán độ tương tự bằng cách tính hàm cosine. Các kết quả mà fastText gợi ý được sắp xếp lại dựa trên thuật toán đo khoảng cách Damerau Levenshtein, dựa trên độ tương tự về các từ giữa hai câu với nhau để đưa ra danh sách gợi ý cho xâu tìm kiếm của người sử dụng.
Hình 2. Các bước ứng dụng hệ thống gợi ý.
TIỀN XỬ LÝ DỮ LIỆU
Dữ liệu lưu trữ trong hai hệ thống phần mềm tại Văn phòng TƯ Đảng là các bài báo thu thập trên Internet theo các chủ đề quan và các tệp số hóa (không mật). Vì vậy, bộ thu thập ngữ liệu cần được xây dựng đảm bảo một số các tính năng: loại bỏ trùng lặp, loại bỏ các từ không phù hợp, soát lỗi chính tả, loại bỏ dấu câu, tách các từ trong câu và lưu mỗi câu trên một dòng trong tệp ngữ liệu. Do đặc trưng của tiếng Việt nên việc tách các câu sử dụng bộ thư viện VnSegmenter [12], và tách các từ sử dụng bộ thư viện RDRSegmenter [3]. Theo đó, các câu được tách từ văn bản bài báo được tiếp tục tách thành các từ (word) tiếng Việt dưới dạng như: cố_gắng, công_nghệ… đối với các từ ghép.
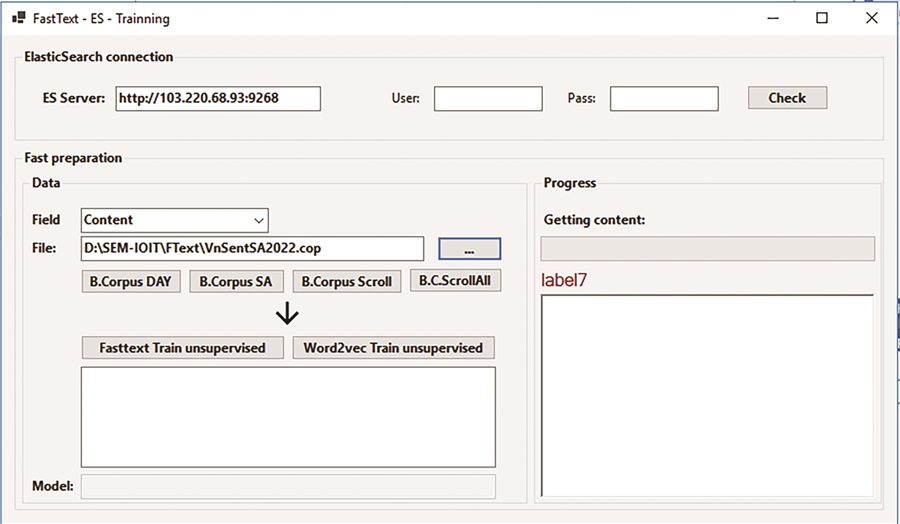
Các bộ thư viện này đảm bảo độ chính xác khi tách câu và từ đạt chất lượng tốt. Nhóm tác giả xây dựng một phần mềm nhỏ để thu thập dữ liệu từ hệ thống phần mềm, thực hiện tiền xử lý dữ liệu và ghi vào tệp ngữ liệu. Đồng thời thu thập và thực hiện tiền xử lý cho khoảng 17 triệu bài báo tại các báo điện tử tiếng Việt lưu trữ trên hệ thống tìm kiếm ElasticSearch từ 2016 đến nay.
Hình 3. FastText thu thập dữ liệu .
Do mục tiêu đặt ra là thực hiện gợi ý hoàn thành câu tìm kiếm cho tiếng Việt, nên bộ ngữ liệu được thu thập đảm bảo độ đa dạng và phức tạp của các dạng câu và từ chuẩn. Các dữ liệu từ query log cũng được sử dụng để tham khảo và xây dựng cho phần front[1]end khi thực hiện gợi ý. Tuy nhiên, dữ liệu này khá ít, nên nhóm tác giả bỏ qua và chỉ tập trung vào phần xây dựng mô hình cho bộ ngữ liệu đã thu thập được.
XÂY DỰNG MÔ HÌNH
Trong các ứng dụng về xử lý ngôn ngữ tự nhiên, học máy,... các thuật toán không thể nhận được đầu vào là chữ với dạng biểu diễn thông thường. Để máy tính có thể hiểu được, ta cần chuyển các từ trong ngôn ngữ tự nhiên về dạng mà các thuật toán có thể hiểu được (dạng số). Bộ thư viện fastText được xây dựng bởi Facebook năm 2016. Thay vì training cho đơn vị word, nó chia text ra làm nhiều đoạn nhỏ được gọi là n-gram cho từ, ví dụ apple sẽ thành app, ppl, and ple, vector của từ apple sẽ bằng tổng của tất cả các n-gram. Do vậy, nó xử lý rất tốt cho những trường hợp từ hiếm gặp, nghĩa là nếu từ không có trong ngữ liệu vẫn có thể sinh ra vector bởi từ được cấu tạo từ các n-gram nói trên.
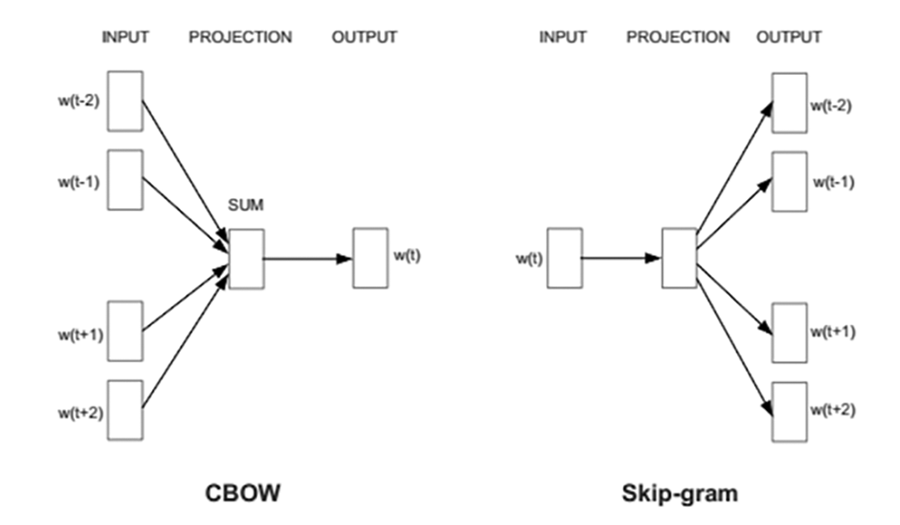
FastText có hai cách xây dựng mô hình vector là CBOW và Skip-gram như Hình 4.
Hình 4. Hai phương pháp xây dựng mô hình vector.
Trong đề án nghiên cứu, nhóm tác giả sử dụng skip-gram để xây dựng mô hình cho bài toán QAC tại Văn phòng TƯ Đảng. Sau khi thu thập và xây dựng bộ ngữ liệu, nhóm tác giả áp dụng fastText và thực hiện huấn luyện mô hình sử dụng phương pháp skip-gram với n=3. Các tham số huấn luyện được điều chỉnh căn cứ trên kết quả gợi ý.
PHƯƠNG PHÁP RANKING
Trong các báo cáo về các phương pháp ranking đã nghiên cứu, nhóm tác giả nhận thấy fastText có khả năng học mối quan hệ của các từ trong sự tương đồng ngữ nghĩa. Điều đó có nghĩa rằng, từ đầu vào của người dùng, fastText có thể gợi ý cho ta những từ tương tự về mặt ngữ nghĩa. Ngoài ra, những từ và câu có khoảng cách Damerau Levenshtein thấp cho ta những câu có các từ và ký tự giống nhau được ưu tiên vì trong đa số trường hợp, các câu có các từ giống nhau cho ra kết quả gần với kỳ vọng của người dùng.
KIẾN TRÚC HỆ THỐNG QAC
Sau khi đã huấn luyện và thử nghiệm độ chính xác của mô hình, nhóm tác giả thực hiện triển khai hệ thống gợi ý này như Hình 5.
Hình 5. Mô hình triển khai.
Bằng cách áp dụng bộ công cụ phát triển Visual Studio 2019, .NET 5.0, nhóm tác giả triển khai xây dựng dịch vụ web AutoSuggest triển khai tại máy chủ, đồng thời xây dựng thêm một số cơ sở dữ liệu nhỏ lưu trữ cache của kết quả tìm kiếm nhằm tăng cường trải nghiệm người dùng. Lựa chọn sử dụng Web service giúp mở rộng khả năng gợi ý khi tìm kiếm của người dùng cho các ứng dụng sẽ xây dựng trong tương lai tại Văn phòng TƯ Đảng. Theo đó, khi cần các hệ thống gọi hàm API với tham số là xâu tìm kiếm, hệ thống sẽ trả về danh sách các kết quả có tương đồng về mặt ngữ nghĩa để có thể lựa chọn.
MỘT SỐ ĐÁNH GIÁ
Nhóm tác giả đã thực hiện huấn luyện mô hình với dữ liệu đã thu, làm sạch, fastText cho kết quả rất khả quan trên cả phương pháp cbow và skip-gram. Kích thước mô hình sau khi huấn luyện là tương tự nhau (tệp mô hình khoảng 1GB cho bộ ngữ liệu 57GB plain-text được làm sạch từ khoảng 17 triệu bài báo thu thập từ 2016 đến nay). Thời gian huấn luyện mô hình khoảng 3 tiếng trên cấu hình máy chủ khá mạnh (Intel Xeon(R) Platinum 8160 – 16 Processors 2.10GHz), 64GB RAM).
Tệp ngữ liệu thu thập được có nội dung là các từ được tách với độ chính xác cao, đảm bảo chất lượng.
Hình 6. Nội dung tệp ngữ liệu.
Trong quá trình thu thập, có khá nhiều ký tự và các từ viết sai lỗi chính tả được ghi vào tệp ngữ liệu, vì vậy nhóm tác giả áp dụng phương pháp hậu kiểm, nghĩa là kết quả gợi ý sẽ được kiểm tra trong bộ từ điển tiếng Việt, nếu không có sẽ được loại bỏ. Từ điển này nhóm tác giả dùng từ điển sử dụng trong bộ RDRSegmenter, khoảng 35.000 từ, bổ sung thêm các từ cần thiết.
Nhóm tác giả điều chỉnh và sử dụng các tham số dưới đây trong quá trình huấn luyện fastText:
- Lr (learning rate) và dim (dimension) với các giá trị tương ứng là 0.05 và 100. Lý do thực hiện điều chỉnh để tránh cho việc bỏ qua các giá trị cực trị địa phương bằng cách giảm bớt hệ số học lr, đồng thời đặt kích thước của vector từ trong mô hình về giá trị 100 để giảm bớt kích thước tệp mô hình sau huấn luyện.
- Minn và maxn được thay đổi cho phù hợp với tiếng Việt, tương ứng là 3, 5.
- Hàm loss được sử dụng là hàm softmax. Sau khi xây dựng bộ API dùng chung và tích hợp với phần mềm hệ thống thông tin tổng hợp, kết quả gợi ý là rất phù hợp với định hướng ban đầu của đề án. Hệ thống cho phép người dùng có thể hoàn thành từ khóa và gợi ý các từ khóa dựa trên xâu ký tự người dùng nhập vào.
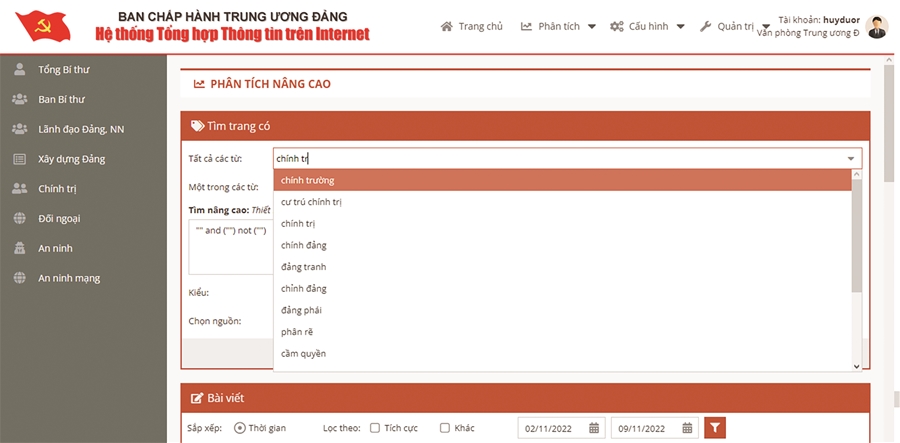
Hình 7. Gợi ý cho xâu ký tự “chính tr”.
Lưu ý rằng, từ khóa “chính trị” chưa được nhập đầy đủ.
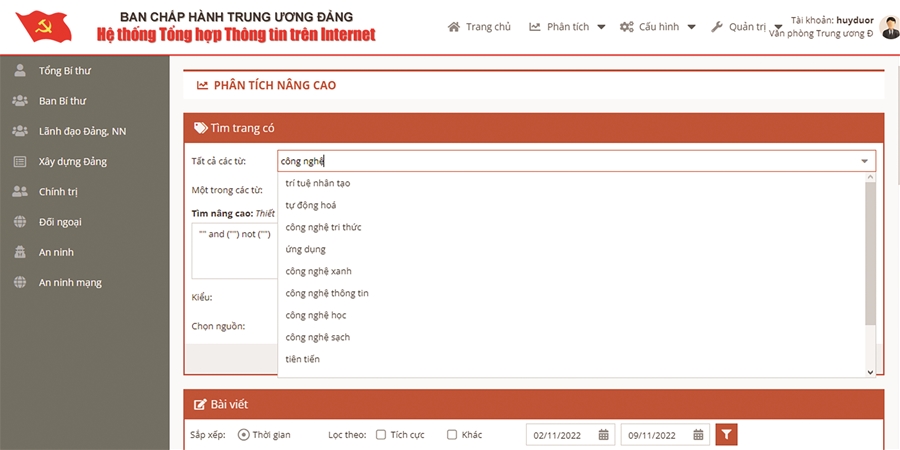
Hình 8. Gợi ý cho từ khóa “công nghệ” .
Có thể nhận ra tác dụng khi sử dụng bộ ngữ liệu là bao trùm của các lĩnh vực quan tâm: chính trị, xây dựng Đảng, khoa học, công nghệ, xã hội,... Việc sử dụng gộp toàn bộ nội dung các bài báo trên báo điện tử để xây dựng bộ ngữ liệu cho thấy kết quả khả quan.
Tuy nhiên, đối với một số thuật ngữ ít xuất hiện trên báo, hoặc tần suất xuất hiện ít, chẳng hạn như các thực thể tên địa danh, tên người, hệ thống gợi ý còn giới hạn do xác suất xuất hiện cùng với từ khóa nhập vào của người dùng trong bộ ngữ liệu là thấp. Trường hợp này có thể tăng tham số k lên một ngưỡng cao hơn, ví dụ 30 kết quả gợi ý cho một từ khóa hoặc cập nhật thêm các “từ khóa” là tên địa danh, tên người,... vào từ điển từ khóa.
KẾT LUẬN
FastText là kiến trúc mạng nơ ron có nhiều lớp, được sử dụng để xây dựng mô hình vector cho văn bản, tập trung chủ yếu dưới dạng vector cho các từ thông qua lấy trung bình vector cho các n-gram của từ đó, do vậy, nó có khả năng trả về vector cho các từ “chưa biết” trong bộ từ vựng bằng cách cộng các vector n-gram có sẵn lại. Tuy nhiên, để có thể gợi ý cả câu từ một đoạn người dùng nhập vào sẽ khó khăn, mặc dù fastText có thể trả về vector cho một đoạn chứa nhiều từ đã được huấn luyện. Độ chính xác về tương đồng ngữ nghĩa là rất tốt, hoạt động nhanh, cho phép fastText có thể triển khai cho các bài toán thực tế, thậm chí trên các thiết bị smartphone [1].
Trong thời gian tới, sau khi đánh giá hiệu quả áp dụng fastText, nhóm tác giả sẽ nghiên cứu và ứng dụng mô hình ngôn ngữ BERT, Bidirectional Encoder Representations from Transformers, cho phép biểu diễn mối quan hệ giữa các từ trong câu tốt hơn so với fastT
TÀI LIỆU THAM KHẢO
Manojkumar Rangasamy Kannadasan, Grigor Aslanyan, “Personalized Query Auto-Completion Through a Lightweight Representation of the User Context”, https://doi.org/10.48550/ https://arxiv.org/abs/1905.01386 .
Fei Cai and Maarten de Rijke. 2016. A Survey of Query Auto Completion in Information Retrieval. Foundations and Trends in Information Retrieval 10, 4 (2016), 273–363. https://doi.org/10.1561/1500000055
Dae Hoon Park and Rikio Chiba. A neural language model for query auto-completion. In SIGIR, 2017
Dat Q.Nguyen and Dai.Q.Nguyen, Thanh Vu, Mark Dras, and Mark Johnson, “A Fast and Accurate Vietnamese Word Segmenter”, Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018), p2582—2587, 2018.
Bhaskar Mitra and Nick Craswell. Query auto-completion for rare prefixes. In CIKM, 2015.
A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jegou, T. Mikolov, “fastText.zip: Compressing Text Classification Models”, arXiv:1612.03651.
Mikolov, Tomas; Sutskever, Ilya; Chen, Kai; Corrado, Greg; Dean, Jeffrey (2013). “Distributed Representations of Words and Phrases and their Compositionality”. arXiv:1310.4546
Piotr Bojanowski, Edouard Grave, Armand Joulin, Tomas Mikolov, “Enriching Word Vectors with Subword Information”, arXiv:1607.04606, 2016
Po-Wei Wang, Huan Zhang, Vijai Mohan, Inderjit S. Dhillon, and J. Zico Kolter. Realtime query completion via deep language models. In SIGIR eCom, 2018.
Sida Wang, Weiwei Guo, Huiji Gao, Bo Long, Efficient Neural Query Auto Completion, CIKM ‘20: Proceedings of the 29th ACM International Conference on Information & Knowledge Management, 2020.
Taihua Shao et al, “Query Auto-Completion Based on Word2vec Semantic Similarity ”, 2018 J. Phys.: Conf. Ser. 1004 012018
Thanh Vu, Dat Quoc Nguyen, Dai Quoc Nguyen, Mark Dras and Mark Johnson, “VnCoreNLP: A Vietnamese Natural Language Processing Toolkit.”, In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, NAACL 2018, pages 56-60.
Tác giả: Đào Văn Thành, Trần Thanh Tùng, Trần Đức Minh



 Luật số 91/2025/QH15: Luật Bảo vệ dữ liệu cá nhân 2025
Luật số 91/2025/QH15: Luật Bảo vệ dữ liệu cá nhân 2025
 5 cách giúp hạn chế việc rò rỉ thông tin cá nhân khi sử dụng Internet
5 cách giúp hạn chế việc rò rỉ thông tin cá nhân khi sử dụng Internet
 Một số cách nhận diện website giả mạo để tránh bẫy lừa đảo trực tuyến
Một số cách nhận diện website giả mạo để tránh bẫy lừa đảo trực tuyến
 Hướng dẫn triển khai Kế hoạch số 02 về thúc đẩy chuyển đổi số đáp ứng yêu cầu sắp xếp, tổ chức lại bộ máy
Hướng dẫn triển khai Kế hoạch số 02 về thúc đẩy chuyển đổi số đáp ứng yêu cầu sắp xếp, tổ chức lại bộ máy
 Ứng dụng trí tuệ nhân tạo hỗ trợ cải cách thủ tục hành chính trong giai đoạn chuyển đổi số hiện nay
Ứng dụng trí tuệ nhân tạo hỗ trợ cải cách thủ tục hành chính trong giai đoạn chuyển đổi số hiện nay
 WormGPT 4 và KawaiiGPT: Dark LLM mới thúc đẩy tự động hóa tội phạm mạng
WormGPT 4 và KawaiiGPT: Dark LLM mới thúc đẩy tự động hóa tội phạm mạng
 Nhiệm vụ và giải pháp trọng tâm của Nghệ An trong triển khai thực hiện Nghị quyết 57-NQ/TW của Bộ Chính trị
Nhiệm vụ và giải pháp trọng tâm của Nghệ An trong triển khai thực hiện Nghị quyết 57-NQ/TW của Bộ Chính trị